Introduction | Reusability aims at being able to reuse a project for a similar customer/task.
Adaptive projects adapt easily to changes in data and do not require multiple similar adaptations in different nodes. |
Use identifiers instead of columns if possible | CORE STEPS: - Transform data nodes from a horizontal to vertical structures
- Pivotize as late as possible if ever back into the horizontal structure
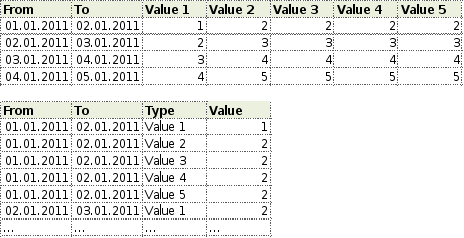
DISCUSSION: - Easier calculations (e.g., with the Formula Operator) as calculations only have to be defined once
- Changes in the number of value types are possible without adaptation
- More data has to be stored
|
Use identifiers instead of similar data nodes | CORE STEPS: - As early in the process as possible add additional columns to distinguish the data sets and then append them with the Merge Data operator.
- Separate data as late as possible
EXAMPLE:
Instead of two data nodes that are structurally identical

Make one with an additional column (Record date)
DISCUSSION: - Easier calculations (e.g., with the Formula Operator) as calculations only have to be defined once
- Changes in the number of value nodes and the data in the additional column used are possible without adaptation
- More data has to be stored
|
Avoid data in names | It is good practice to avoid names like "Male -2006" (at all or at least as long as possible).
If a more general way can be found adaptation is avoided when data changes. |