Calculation methods
This page explains the calculation methods of the Scaling 8.0 operator. The calculation method for an operation is set by the parameter "Calculation method" of the operator.
A calculation method determines
- whether a data interval is allocated to a scale interval (incrementing the value of the "Result" or "CNT_" fields of the result table), and
- the values in the "Value" columns of the result table based on the "Value" columns in the input table.
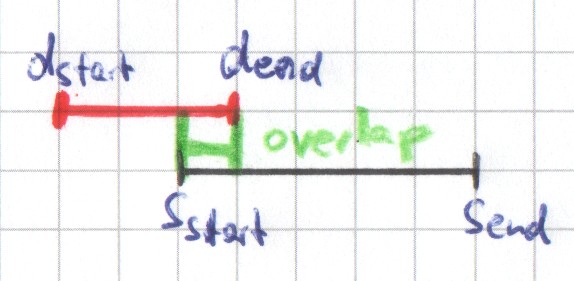
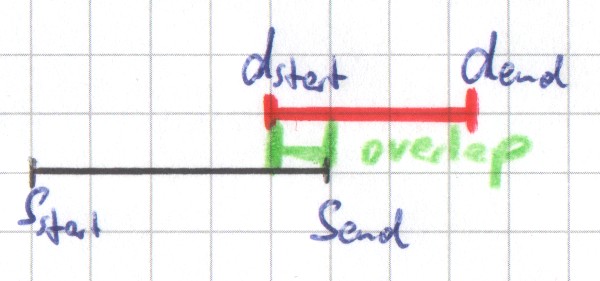
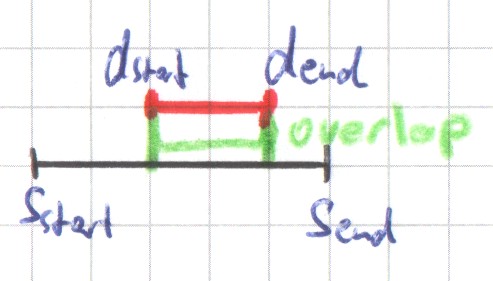
A data interval and a scale interval can overlap. In particular, the data interval can start or end in, or completely overlap a scale interval (see introduction of Scaling 8.0 for examples). The decision of whether a data interval is allocated to a scale interval depends on this relation. Depending on the calculation method, it can happen that a data interval is allocated to zero, one, or many scale intervals and vice versa.
If a data interval is allocated to a scale interval, then the data interval's values can influence the scale interval's values in different ways. For example, the values of the scale interval can be the sums of the values of the data intervals allocated to the scale interval . Other methods consider the percentage to which one interval overlaps the other.
The calculation methods can be divided in two categories: Methods, that focus on (1.) the allocation condition for a data interval to a scale interval, and methods, that focus on (2.) the calculation of the values. Methods of the former category calculate the values in the same way and methods of the latter category have the same allocation condition (TODO stimmt das?).
The next section gives an intuitive overview on the different calculation methods with respect to the allocation of data intervals and the determination of the values in a scale interval. It is followed by a section defining the methods in a more formal way.
Intuitive overview
The following table gives an intuitive overview over the currently implemented calculation methods and some possible extensions.
In the table, we abbreviate the data interval by d and the scale interval by s. The first nine methods differ in their allocation condition. The other methods all allocate a data interval to a scale interval if they overlap. These methods differ in the calculation of the values.
Formal definitions for table below
The formal parts of the overview below are based on a set of variables and a function.
In particular, the triple d = (dstart, dend, dval) represents an interval defined in a data row of the input table (data interval), where
dstartis the start time ofd("From" column of the input table),dendis the end time ofd("To" column of the input table), and- dval is a sequence of decimal numbers (see Data Types) defined for
d(the values in columns defined in setting "Count"), which defaults to [1].
Note that the length of dval is the same for all rows as it equals the number of columns defined in column setting "Count".
Further, we use dlength = dend - dstart to describe the length of d.
The quadruple s = (sstart, send, scnt, sval) represents an interval of fixed length defined the scale (scale interval), where
sstartis thessendis the end time ofsscntis an integer indicating the number of data intervals allocated tos("CNT_" or "Result" column of the result table), and- sval is a sequence of decimal numbers of length equal the number of columns defined in column setting "Count", each number representing the sum over the values computed for each value at the same index of dval for each allocated data interval
d("Value" columns of the result table),
Further, we use slength = send - sstart to describe the length of s. This value is the same for rows of the result table. It is defined by the parameter "Scaling" that defines the scaling intervals.
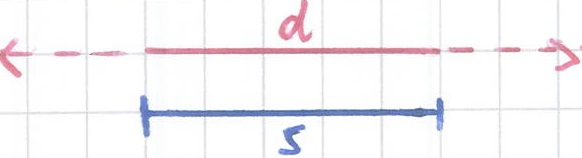
The function overlap(s,d) takes as input two intervals. It returns an Integer representing the time the two intervals overlap.
For example, the figure below shows a data interval d as a red line and a scale interval s as a black line. The intervals d and s overlap two time units, therefore overlap(s,d) = 2.
The function overlap(s,d) hence is defined as follows.
overlap: Intervals x Intervals → Integers >= 0 (overlap maps two Intervals to a non-negative Integer)
| if |
|
if |
| |
if |
| |
if |
| |
otherwise |

Name in version 7.0 | Proposed name for version 8.0 |
|
|
| Formal condition for (if and only if) | |||
|---|---|---|---|---|---|---|---|---|
( |
( |
|
( | |||||
50% in scale | 50% of scale interval in data interval |
|
|
(note solid red line) |
( |
(note solid red line) | Zero, one, or many |
|
100% in scale | 100% of scale interval in data interval |
|
| - | - | - | Zero, one, or many |
|
New, see FLEX-349 | 50% of data interval in scale interval |
| n/a | - (tie, allocation of | n/a | n/a | Zero or one |
|
Possible addition related to FLEX-349 | 100% of data interval in scale interval | s overlaps 100% of d | - | - |
| - | Zero or one | |
Possible addition | Largest part of data interval in scale interval |
|
| - (tie, allocation of |
|
| Exactly one | |
Start time in scale | Start time in scale interval or overlaps 100% of scale interval |
|
| - |
|
| At least one |
|
End time in scale | End time in scale interval or overlaps 100% of scale interval |
|
|
|
| - | At least one |
|
Count start time only | Start time in scale interval |
| - | - |
|
| Exactly one |
|
Count final time only | End time in scale interval |
| - |
|
| - | Exactly one |
|
Proportional time*value | Value proportional to data in scale |
|
|
|
|
| At least one |
|
Proportional value | Overlap in hours |
|
|
|
|
| At least one |
|
Distribute value in pattern | ? |
|
|
|
|
| At least one |
|
Smallest value in the pattern | Smallest value of allocated data |
|
|
|
|
| At least one |
|
Largest value in pattern | Largest value of allocated data |
|
|
|
|
| At least one |
|
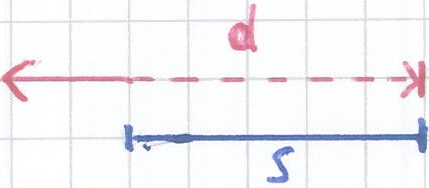
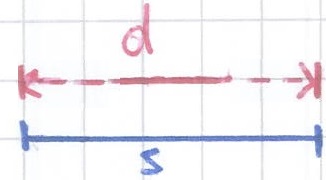
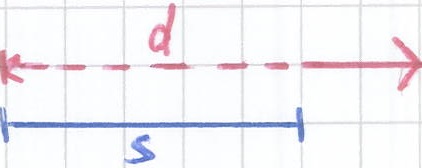
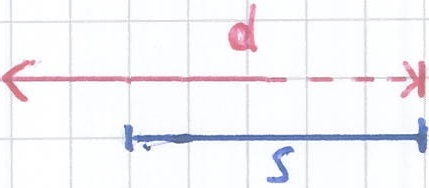
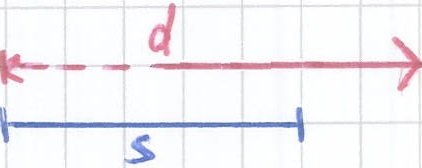
![]() Note for DST* handling supported starting from op-v 8.2
Note for DST* handling supported starting from op-v 8.2
All records that have an invalid start or end date in the transition period at the beginning of dst will be ignored.
Name in version 7.0 | Condition for d to be allocated to s | Calculation of | Notable error behaviour |
|---|---|---|---|
50% in scale | If and only if | svali = If parameter "Count" is not set, then these columns are omitted.
the values are not adjusted, only for counting, when no value column is specified. | |
100 % in scale | If and only if | As in option "50% in scale" | |
Start time in scale | If and only if | As in option "50% in scale" | |
End time in scale | If and only if | As in option "50% in scale" | |
Count start time only | If and only if | As in option "50% in scale" | |
Count final time only | If and only if | As in option "50% in scale" | |
Proportional time*value | If and only if | svali = overlap | Error if no value column defined |
Proportional value | If and only if | svali = overlap
| Error if no value column defined |
Distribute value in pattern | If and only if | Like "Proportional value" no implementation defined (not in 8.0, 8.1 or 8.2) | Error if no value column defined |
Smallest value in the pattern | If and only if | Value column is required, otherwise 1 is taken.
| If no value column defined, then input table is returned with additional "Result" and "CNT_" columns |
Largest value in pattern | If and only if | Value column is required, otherwise 1 is taken.
| If no value column defined, then input table is returned with additional "Result" and "CNT_" columns |
Hours to staffing |
both intervals (d and s) are adapted to DST | ||
Staffing to hours |
both intervals (d and s) are adapted to DST | ||
Maximum duration of the data row | If and only if | svali =
|