Identifier instances
Summary
Finds an identifier in one or more columns. The different instances (= values) of a column and/or several columns are displayed.
Configuration
Input settings of existing table
Name | Value | Opt. | Description | Example |
|---|---|---|---|---|
Identifier | System.Object | - | Which columns should be evaluated for the identifier? | - |
Settings
Name | Value | Opt. | Description | Example |
|---|---|---|---|---|
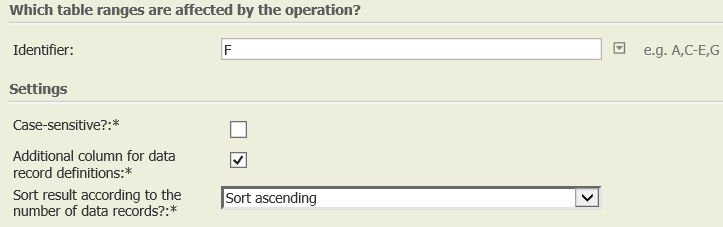
Case-sensitive? | System.Boolean | opt. | When checking for sameness, should upper and lower case letters be considered? | - |
Additional column for data record definitions | System.Boolean | opt. | Should an additional column showing the number of duplicate data records be output? | - |
Sort result according to the number of data records? | System.String
| opt. | Should the result be sorted by the number of identical data records? | - |
Want to learn more?
Examples
Example: Using "Identifier instances"
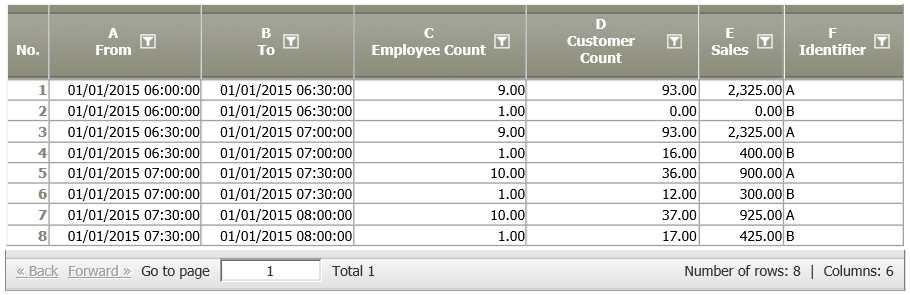
Situation | The following data node contains information on employee, customer and sales figures in different locations (column F). We want to count how many locations there are, and how many times each employee count exists in the data.
|
|---|---|
Settings | Add the operator "Identifier instances" to the data node. Choose which column you would like to count
|
Result | Identifier = F results in the following data node:
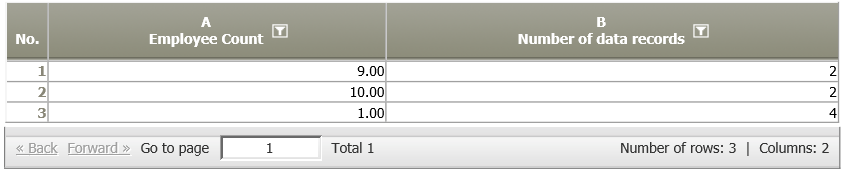
Identifier = C results in the following data node:
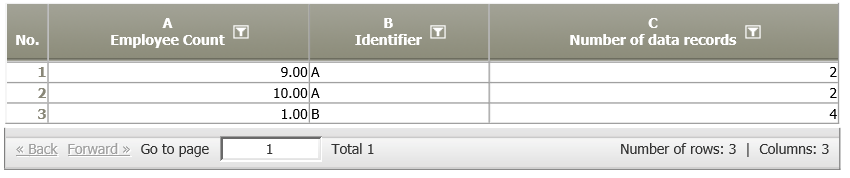
Identifier = C, F results in the following data node (combinations):
|

Troubleshooting
Please make sure if "case sensitive" should be checked or not, especially when using this operation in combination with others (e.g., Merge data 5.0).