Merge data 5.0
Summary
Merge columns from the current table with columns from another data node's result table based on one or more key columns. This operator implements various join operations for relational databases.
Configuration
Settings
Name | Value | Opt. | Description |
|---|---|---|---|
How should the data be merged? | System.String
| - | An option that defines which rows and which columns from which source(s) are to be included in the resulting table. See table "Overview of merging options and comparison to set theory and SQL" below for details. See table "Examples" at the bottom of this page for examples for each of the options. |
Data source | System.Int32 | - | The name of the data node whose result table is to be merged with the current table. |
Merge the following columns with columns from the data source | System.String | opt. | A sequence of columns of the current table that serve as keys, i.e., that will be used to match rows of the other table. The number of columns in this parameter and the type of the columns must equal the number of columns in parameter "Columns used as key in data source 1" and their type. |
Columns used as key in data source 1 | System.String | opt. | A sequence of columns of the result table of the data node specified in parameter "Data source" that serve as keys, i.e., that will be used to match rows of the current table. The number of columns in this parameter and the type of the columns must equal the number of columns in parameter "Merge the following columns with columns from the data source" and their type. For further information see also Column references |
Ignore Time? | System.Boolean | - | If checked, comparisons will only consider the date and ignore the time of keys that are of type Date. |
Generate blank row if nothing has been found | System.Boolean | opt. | If checked, a table containing a single row is returned instead of an empty table. This row contains NULL in numerical columns and date columns and the text defined in parameter "Text fields content for blank line" in text columns. |
Text fields content for blank line | System.String | opt. | The text to be inserted in text columns if parameter "Generate blank row if nothing has been found" is checked. |
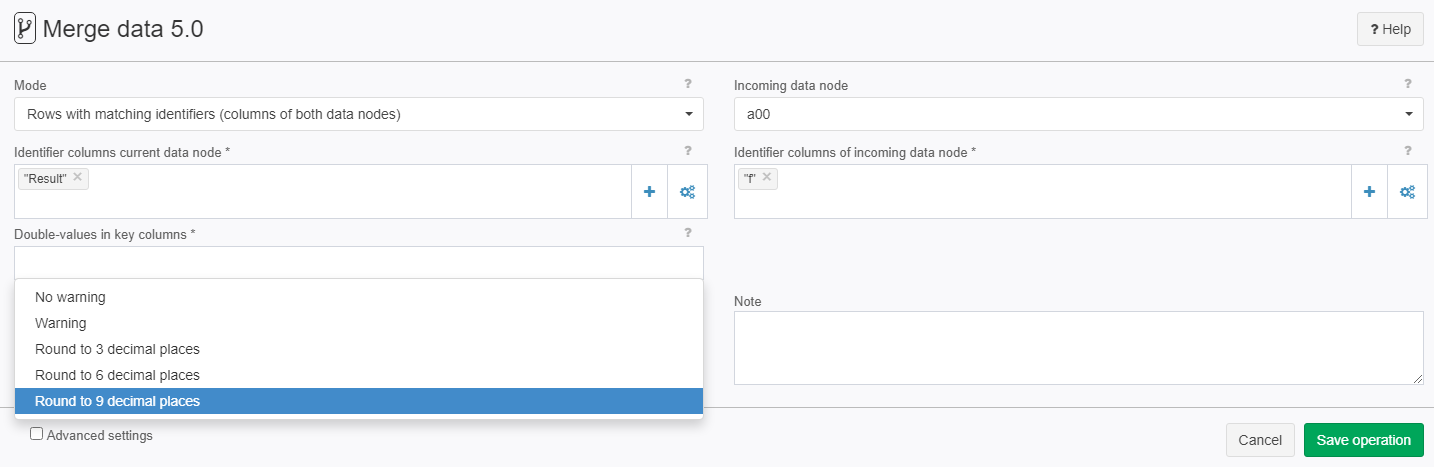
Double-values in key columns | System.String
| - | Default is Warning If columns of data type double are used as Identier than one of the comparison behaviours must be selected.
|
Column order | System.String | opt. | Spaltenreihenfolge |
Want to learn more?
Merge data from the current table with data from another data node's result table based on one or more key columns. This operation results in a table containing rows with matching keys and the set of columns defined in parameter "How should the data be merged?".
Screenshot
Overview of merging options and comparison to set theory and SQL
The following table describes the merge options set in parameter "How should the data be merged?" in detail. These options define which rows and which columns of the two tables are contained in the result table and how they are merged.
Keys play a central role in the merge for all options except "Append (same table structure required)" and "Cartesian product". They are responsible for the selection of rows from the two data sources. The keys are defined in parameters "Merge the following columns with columns from the data source" and "Columns used as key in data source 1". For each data source, more than one column can be defined as key. The number and types of keys set for each data source have to match. Keys given as Integer are treated as Decimals, therefore columns of these types also match.
Note that key values in the data sources are not necessarily unique, i.e., a key can occur in more than one row of a table. In this case, the set theory definition in the table is not adequate for options 1 to 4, 10, and 11. In this case, the result table contains the cartesian product of multiply occurring keys. E.g., if table A contains two occurrences of key A.1 and table B two occurrences of B.1, then the result table contains four rows merging each row with key A.1 with each row with key B.1.
The column "Set theory" in this table describes how the rows are selected according to the keys, i.e., which set of keys is contained in the result table.
The column "Result structure" describes which columns are included in the selected rows (described in column "Set theory"). For better readability, the term "key" is used although a sequence of keys, i.e., multiple columns, can be defined as key. The suffix "fields" refers to all fields of a selected row except those fields that are used as key.
For each option, the table also shows a rough correspondence to an SQL statement,
The current table is referred to by "A" and the table from another data node is referred to by "B".
How should the data be merged? old name | Deutsch alte Bezeichnung | SQL | Set theory | Result column structure | Description | |
|---|---|---|---|---|---|---|
1 | Rows with matching identifiers (columns of both data nodes) Intersection (same keys) | Zeilen mit übereinstimmenden Identifizierern (Spalten beider Datenknoten) Schnittmenge (gleiche Schlüssel) | SELECT * FROM A INNER JOIN B ON A.key = B.key | A.key n B.key (Intersection) | A.key; A.fields; B.fields | The result table contains a row for each key that occurs in both tables. For each row, all columns from both tables are added. Except for the key column, columns with the same name are renamed. |
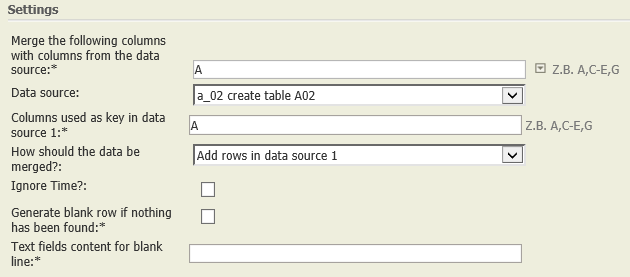
2 | Add to rows of current data node Add rows in data source 1 | Zeilen des aktuellen Datenknotens ergänzen Zeilen aus Datenknoten 1 ergänzen | SELECT * FROM A LEFT OUTER JOIN B ON A.key = B.key | (A.key n B.key) u A.key | A.key; A.fields; B.fields | The result table contains a row for each key that occurs in the current table. To each row, all columns from both tables are added. Rows with keys in both tables are merged. Except for the key column, columns with the same name are renamed. |
3 | Add to rows of incoming data node Add rows in data source 2 | Zeilen des eingehenden Datenknotens ergänzen Zeilen aus Datenknoten 2 ergänzen | SELECT * FROM A RIGHT OUTER JOIN B ON A.key = B.key | (A.key n B.key) u B.key | A.key; A.fields; B.fields | The result table contains a row for each key that occurs in the other data node's table. To each row, all columns from both tables are added. Rows with keys in both tables are merged. Except for the key column, columns with the same name are renamed. |
4 | Add to rows of both data nodes Add rows in both data sources | Zeilen beider Datenknoten ergänzen Zeilen beider Datenknoten ergänzen | SELECT * FROM A FULL OUTER JOIN B ON A.key = B.key | A.key u B.key (Union) | A.key; A.fields; B.fields | The result table contains a row for each key that occurs in either of the two tables. For each row, all columns from both tables are added. Rows with keys in both tables are merged. Except for the key column, columns with the same name are renamed. |
5 | Append (same table structure) Append (same table structure required) | Aneinanderhängen (gleiche Tabellenstruktur) Aneinanderhängen (nur bei gleicher Tabellenstruktur) | SELECT * FROM A UNION SELECT * FROM B | n/a | A.key; A.fields | The result table of the other data node is appended to the current table. Both tables must have the same schema. |
6 | Number of rows occurring only in current data node Keys only used in data source 2? | Anzahl Zeilen ausschließlich im aktuellen Datenknoten Schlüssel aus Datenknoten 1 kommen nur dort vor? | SELECT A.key, COUNT(A.key) FROM A WHERE A.key NOT IN (SELECT B.key FROM B) GROUP BY A.key | A.key \ B.key (Difference) | A.key; # | For all rows of the current table whose key also occurs in the other data node's table, the result table contains the key and its number of occurrences in the current table. |
7 | Number of rows occurring only in incoming data node Keys only used in one data source | Anzahl Zeilen ausschließlich im eingehenden Datenknoten Schlüssel aus Datenknoten 1 kommen nur dort vor? | SELECT B.key, COUNT(B.key) FROM B WHERE B.key NOT IN (SELECT A.key FROM A) GROUP BY B.key | B.key \ A.key (Difference) | B.key; # | For all rows of the other data node's table whose key also occurs in the other data node's table, the result table contains the key and its number of occurrences in the current table. |
8 | Number of rows without reference in the other data node Keys only used in data source 1? | Anzahl Zeilen ohne Bezug im anderen Datenknoten Schlüssel ohne Bezug im anderen Knoten | SELECT A.key, COUNT(A.key) FROM A WHERE A.key NOT IN (SELECT B.key FROM B) GROUP BY A.key UNION SELECT B.key, COUNT(B.key) FROM B WHERE B.key NOT IN (SELECT A.key FROM A) GROUP BY B.key | (A.key u B.key) \ (A.key n B.key) (Symmetric difference) | A.key; # | For all rows whose keys occurs only in either of the tables, the result table contains the key and its number of occurrences in the respective table. |
9 | Cartesian product | Kartesisches Produkt | SELECT * FROM A, B | n/a | A.key; A.fields; B.key; B.fields | The result table contains the cartesian product of the current table and the other data node's table. |
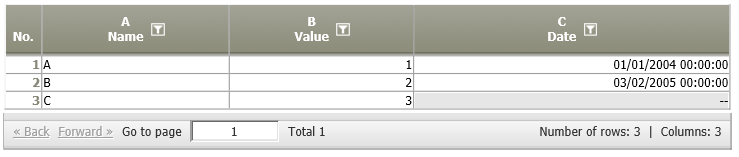
10 | Rows with identifier in incoming data node Rows with common key in data source 2 | Zeilen mit Identifizierer im eingehenden Datenknoten Zeilen mit gemeinsamen Schlüssel in Datenknoten 2 | SELECT * FROM A WHERE A.key IN (SELECT B.key FROM B) | A.key n B.key | A.key; A.fields | The result table contains all rows of the current table, whose key is contained in the other data node's table. |
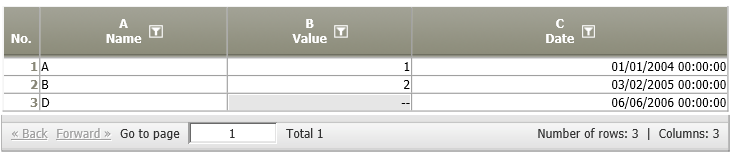
11 | Rows without identifier in incoming data node Rows without common key in data source 2 | Zeilen ohne Identifizierer im eingehenden Datenknoten Zeilen ohne gemeinsamen Schlüssel in Datenknoten 2 | SELECT * FROM A WHERE A.key NOT IN (SELECT B.key FROM B) | A.key \ B.key | A.key; A.fields | The result table contains all rows of the current table, whose key is not contained in the other data node's table. |
More than one key column | SELECT * FROM A LEFT JOIN B ON {A.X <> B.Y AND A.X2 <> B.Y2} |
Examples
Example: Combine two tables using "Intersection"
(Examples for other options see bottom of this page.)
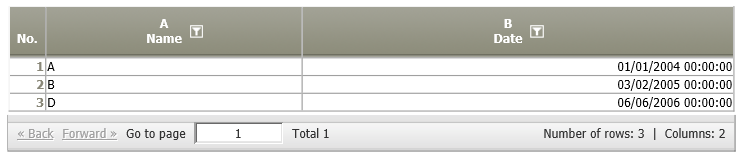
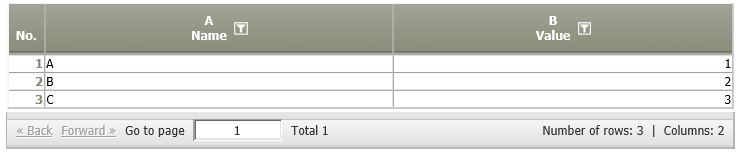
The following tables should be merged:
A01 | A02 |
|---|---|
|
|
Settings |
|
|---|---|
Result | Each row of A01 is compared with each row of A02. If the values of the columns indicated in the first parameter and the third parameter (i.e.,the keys) coincide,
|
Project-File |
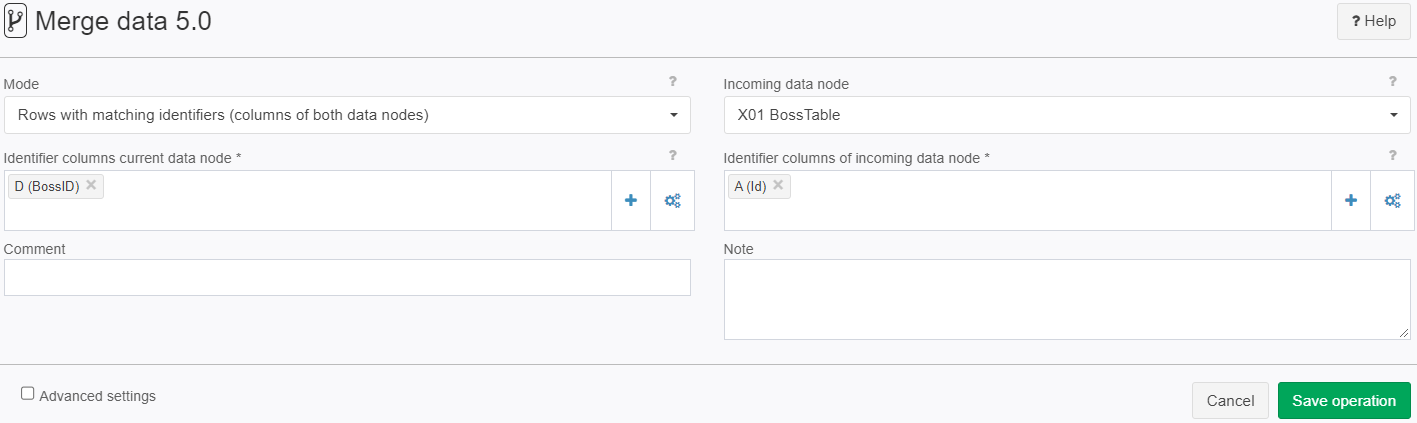
Example: Boss table
Tow tables should be merged in order to better visualize who is whose boss
The following tables should be merged:
A01 | A02 |
|---|---|
Employee table
| Boss table
|


Settings | In the node with table A01.
|
|---|---|
Result |
|
Project File | - |

Examples: Merge options in the Operator
Calculation method | Data nodes to be merged | Settings | Result |
|---|---|---|---|
Rows with matching identifiers (columns of both data nodes)
Zeilen mit übereinstimmenden Identifizierern (Spalten beider Datenknoten)
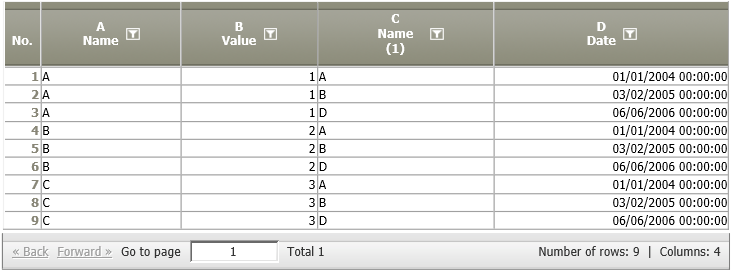
| A01:
A02:
|  | Each row of A01 is compared with each row of A02. If the values of the columns indicated in the first parameter and the third parameter (i.e.,the keys, columns A of both tables) coincide, then the respective row of A01 is completed with the values of the matching row of A02 and shown in the result table.  |
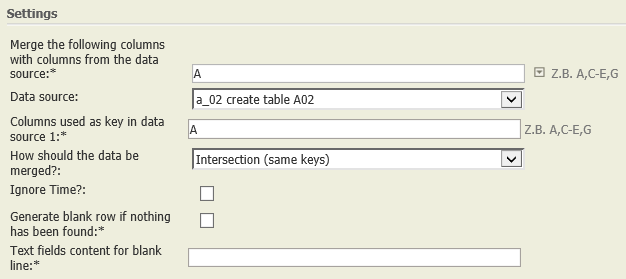
Add rows in data source 1 | A01:
A02:
|
| Each row of A01 is compared with each row of A02. If the values of the columns indicated (i.e., the keys, columns A of both tables) coincide, then the respective row of A01 is completed with the values of the matching row of A02 and shown in the result table. All remaining rows of A02 are also added to the result. Fields of these rows whose columns are not contained in A02 are completed with NULL (denoted by "–", see column "Date").
|
Add rows in data source 2 | A01:
A02:
| 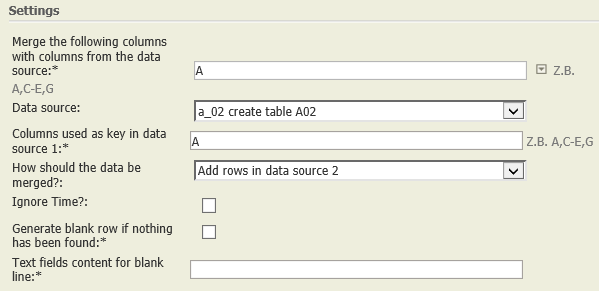 | Each row of A01 is compared with each row of A02. If the values of the columns indicated (i.e., the keys, columns A of both tables) coincide, then the respective row of A02 is completed with the values of the matching row of A02 and shown in the result. All remaining rows of A02 are also added to the result. Fields of these rows whose columns are not contained in A02 are completed with NULL (denoted by "–", see column "Value").
|
Add rows in both data sources | A01:
A02:
| 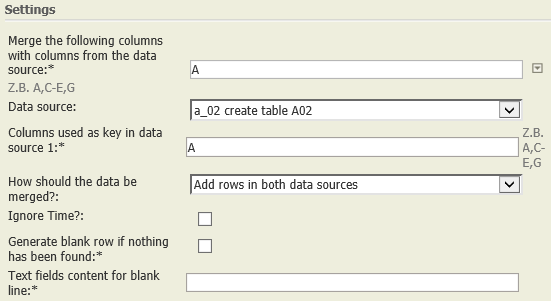 | Each row of A01 is compared with each row of A02. If the values of the columns indicated (i.e., the keys, columns A of both tables) coincide, then the respective row of A01 is completed with the values of the matching row of A02 and shown in the result table. All remaining rows of A01 and A02 are also added to the result. Fields of these rows whose columns are not contained in the other table are completed with NULL (denoted by "–", see columns "Date" and "Value").
|
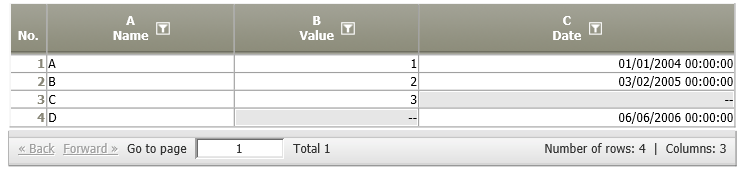
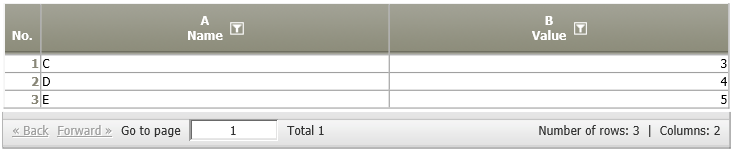
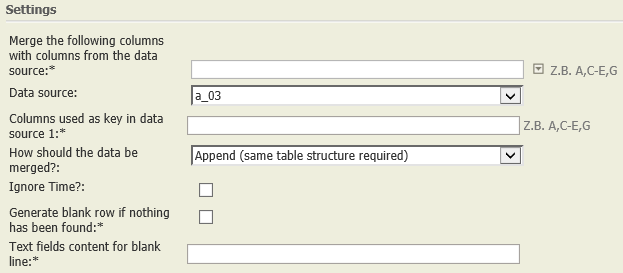
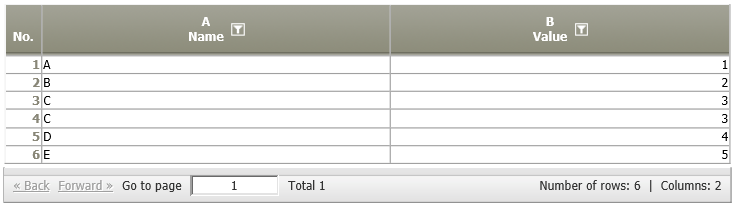
Append (same table structure required) | A01:
A03: |
| Each row of data node A03 is appended to the table of data node A01.
|
Keys only used in data source 1 | A01:
A03: | 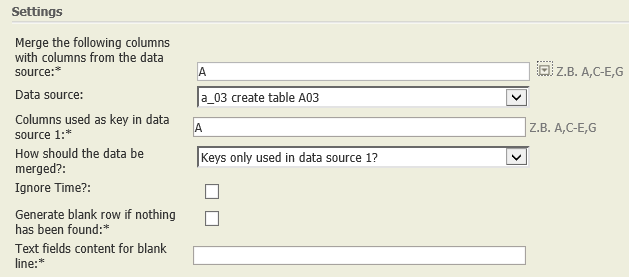 | Each row of A01 is compared with each row of A03 according to their keys (columns A in both tables). Each key which is present only in data node A01 is shown in the result together with its number of occurrences.
|
Keys only used in data source 2 | A01:
A03: | 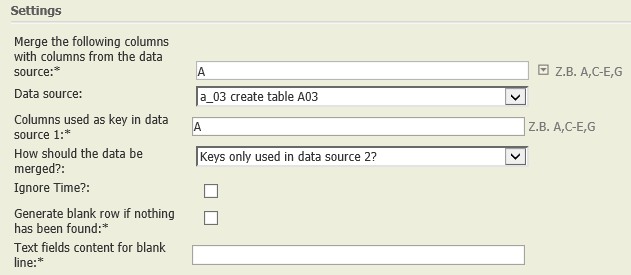 | Each row of A01 is compared with each row of A03 according to their keys (columns A in both tables). Each key which is present only in data node A03 is shown in the result together with its number of occurrences.
|
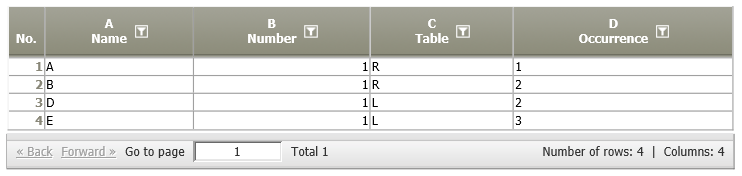
Keys only used in one data source | A01:
A03: | 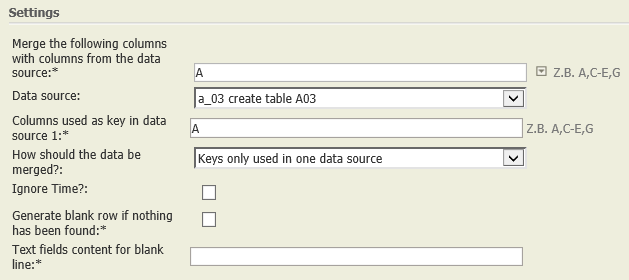 | Each row of A01 is compared with each row of A03 according to their keys (columns A in both tables). Each key which is either only present in either data node A01 or in data node A03 is shown in the result together with its number of occurrences in column "Number", the table where it was found in column "table", and the row number(s) of the table where the occurrences where found in column "Occurrence".
|
Cartesian product | A01:
A02:
| 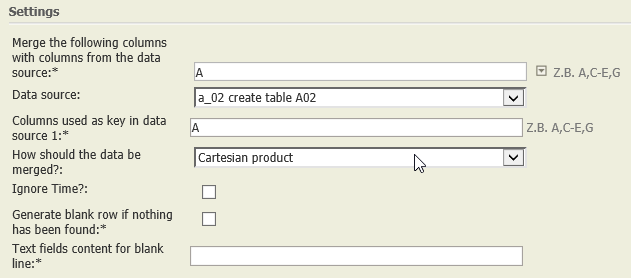 | Each row of A02 is appended to each row of A01.
|
Rows with common key in data source 2 | A01:
A02:
|  | Those rows of data node A01 whose values in column A are also present in column A of data node A02 are shown in the result.
|
Rows without common key in data source 2 | A01:
A02:
| 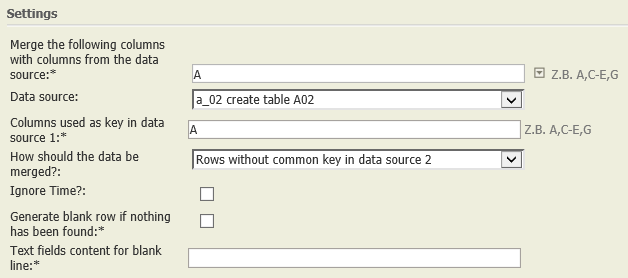 | Those rows of data node A01 whose value in column A is not present in column A of data node A02 are shown in the result.
|




Troubleshooting
Frequent Problems | Solutions |
|---|---|
Caution: You're comparing floating point numbers, which can yield unintended results. Please create text columns of the respective columns using ToString("F3").
|
|
Columns are not entered in corresponding order e.g.
|
|
Wrong selection from the list of nodes (this may sound unlikely but it is not) | The tricks explained under Data Node can help. |
There is a text in the background, even if it does not look like it. e.g. with Fehlerknoten (old wiki) | |
There are different data types in the data nodes (e.g. numbers, once imported as text, once imported as number) | The Formula operator (rowwise) can help converting the data to a common data type. |
TOO MANY colums are marked for comparison. Among them there are columns which do not have common keys (even if e.g. intersection was selected). | |
War rot markiert im Wiki: In combination with other operations (e.g. Identifier instances) if it should be used with or without consideration of upper and lower case letters. | |
War rot markiert im Wiki: Column order should be chosen so that the strongest restrictions are located in the beginning. Typically, FROM-TO should be in the beginning of the list of keys. |
